Diseño Relacional#
1. Definición: Modelo de Datos Relacional#
Concepto Básico#
El modelo de datos relacional es un enfoque de gestión de bases de datos basado en la teoría de conjuntos y la lógica de predicados. Propuesto por Edgar F. Codd en 1970, este modelo organiza los datos en tablas, conocidas como relaciones, donde cada tabla representa una entidad o relación del mundo real. Las tablas están formadas por filas (tuplas) y columnas (atributos). Cada fila de una tabla corresponde a un registro único de la entidad representada.
Estructura de una Relación#
Entidades (Tablas): Representan una colección de caracteristicas de una misma entidad. Por ejemplo, una tabla de
Estudiantespodría incluir columnas comoID,Nombre,Apellido,Fecha de Nacimiento.Atributos (Columnas): Cada columna en una tabla representa una propiedad de la entidad. Por ejemplo, en una tabla
Estudiantes,IDpodría ser un atributo que identifica de manera única a cada estudiante.Tuplas (Filas): Cada fila en una tabla representa una instancia específica de la entidad. Por ejemplo, un estudiante individual en la tabla
Estudiantes.
Ventajas del Modelo Relacional#
Simplicidad: Al organizar los datos en tablas, se facilita la comprensión, manipulación y consulta de la información.
Independencia de los Datos: El modelo relacional permite cambios en la estructura de la base de datos (por ejemplo, en las tablas) sin afectar las aplicaciones que dependen de ella.
Integridad de los Datos: Utiliza restricciones y reglas para asegurar que los datos sean precisos y coherentes.
2. Conceptos del Modelo Relacional#
Relación: Una relación es una tabla que representa una entidad del mundo real o una asociación entre entidades. Las relaciones están formadas por tuplas y atributos.
Atributo: Es cada una de las columnas de una tabla. Cada atributo tiene un dominio, que es un conjunto de valores permitidos para ese atributo.
Dominio: Es el conjunto de valores posibles que un atributo puede tomar. Por ejemplo, el atributo
Géneropodría tener un dominio compuesto por los valoresMasculinoyFemenino.Clave Primaria (Primary Key): Un conjunto de uno o más atributos que identifican de manera única cada tupla en una relación. Es un identificador único y no puede contener valores nulos.
Clave Foránea (Foreign Key): Un atributo o conjunto de atributos en una relación que refiere a una clave primaria en otra relación, estableciendo una relación entre las dos tablas.
3. Propiedades de las Relaciones#
Propiedad de Unicidad: Cada tupla en una relación debe ser única, es decir, no puede haber duplicados de filas dentro de una tabla. Esta propiedad asegura que cada registro en la tabla sea identificable de manera única.
Propiedad de Atomicidad: Los valores de los atributos deben ser atómicos, lo que significa que cada celda en una tabla debe contener un solo valor indivisible. Esto es esencial para asegurar la simplicidad y claridad en la manipulación de los datos.
Propiedad de Ordenación: En el modelo relacional, el orden de las filas y columnas no tiene importancia. Las relaciones son conjuntos de tuplas y, como en cualquier conjunto, el orden de los elementos no es relevante.
3. Atributos Claves#
Clave Primaria#
Definición: Un atributo o conjunto de atributos en una tabla que identifica de manera única cada tupla (fila). La clave primaria es crucial para la integridad de la base de datos y no puede contener valores nulos. Por ejemplo, en una tabla de
Estudiantes, elID del Estudiantepodría ser la clave primaria.Condiciones para la Clave Primaria:
Unicidad: Debe ser único en cada registro.
No nulidad: No puede haber registros con un valor nulo en la clave primaria.
Clave Foránea#
Definición: Un atributo en una tabla que refiere a la clave primaria de otra tabla, estableciendo una relación entre ambas tablas. Por ejemplo, en una tabla de
Inscripciones, elID del Estudiantepuede ser una clave foránea que apunta a la tabla deEstudiantes.Condiciones para la Clave Foránea:
Integridad referencial: Los valores de la clave foránea deben coincidir con valores existentes en la tabla referenciada, o bien ser nulos si la relación lo permite.
4. Reglas de Integridad#
Integridad de Entidad: Asegura que cada tabla en la base de datos tenga una clave primaria que sea única y no nula. Esto garantiza que cada registro sea único y no exista ambigüedad en la identificación de registros.
Integridad Referencial: Establece que las claves foráneas en una tabla deben corresponder a valores existentes en la tabla referenciada. Esta regla asegura que las relaciones entre tablas sean coherentes y previene la existencia de referencias inválidas.
Integridad de Dominio: Asegura que los valores de un atributo deben pertenecer al dominio específico de ese atributo. Esto previene la entrada de datos que no sean válidos o que no tengan sentido dentro del contexto de la base de datos.
5. Diccionario de Datos#
Definición: Un diccionario de datos es un repositorio centralizado que contiene descripciones de los elementos de datos dentro de una base de datos. Incluye detalles como nombres de tablas, nombres de columnas, tipos de datos, restricciones, claves, relaciones entre tablas y mucho más.
Aplicación: Sirve como una herramienta crucial para diseñadores, desarrolladores y administradores de bases de datos, proporcionando un punto de referencia que asegura consistencia y comprensión común en el equipo de trabajo.
Importancia: El diccionario de datos facilita el diseño, implementación, y mantenimiento de la base de datos. También es vital para la documentación, ya que proporciona una descripción completa y precisa de los datos almacenados, lo que es crucial para la auditoría, cumplimiento normativo y la evolución del sistema.
6. Reglas de Codd#
Primero recordemos los niveles de diseño de bases de datos:
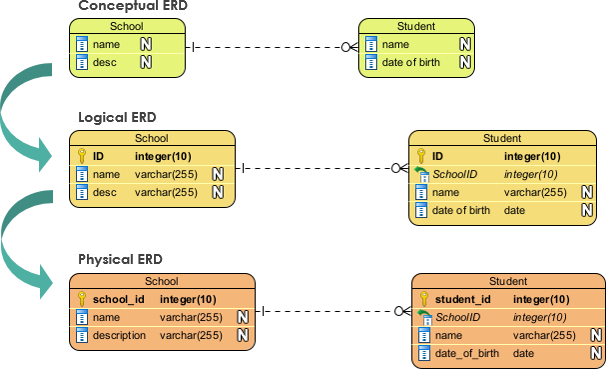
Figura 1 Niveles de diseño de bases de datos. Tomado de Visual Paradigm.#
Edgar F. Codd propuso 12 reglas que definen qué características debe tener un sistema de bases de datos para ser considerado verdaderamente relacional. Aunque la mayoría de los sistemas modernos no cumplen con todas las reglas de Codd, estas sirven como principios guía.
Regla 0: Regla fundamental. Todo sistema que se defina como sistema de gestión de base de datos relacional, o se anuncie como tal, ha de poder gestionar las bases de datos exclusivamente con sus capacidades relacionales.
Regla 1: Regla de la información. Toda la información en una base de datos relacional se representa de forma explícita en el nivel lógico y exactamente de una manera: con valores en tablas.
Regla 2: Regla del acceso garantizado. Se garantiza que todos y cada uno de los datos (valor atómico) de una base de datos relacional son accesibles lógicamente mediante una combinación de nombre de tabla, valor de clave primaria y nombre de columna.
Todos los datos deben ser accesibles sin ambigüedad. Esta regla es esencialmente una nueva exposición del requisito fundamental para las claves primarias. Dice que cada valor escalar individual en la base de datos debe ser lógicamente direccionable especificando el nombre de la tabla, la columna que lo contiene y la clave primaria.
Regla 3: Regla del tratamiento sistemático de valores nulos. Los sistemas de gestión de base de datos plenamente relacionales admiten los valores nulos (distintos de la cadena vacía, los blancos, los ceros o cualquier otro número) para representar la información desconocida y la inaplicable de manera sistemática e independiente del tipo de dato .
Regla 4: Catálogo dinámico en línea basado en el modelo relacional. La descripción de la base de datos se representa a nivel lógico igual que los datos comunes, de modo que los usuarios autorizados pueden utilizar el mismo lenguaje relacional en su consulta que el que aplican a los datos comunes.
El sistema debe soportar un catálogo en línea, el catálogo relacional, que da acceso a la estructura de la base de datos y que debe ser accesible a los usuarios autorizados.
Regla 5: Regla del sublenguaje de datos completo. Un sistema relacional debe permitir varios lenguajes y varios modos de uso terminal (como rellenar formularios, por ejemplo). Sin embargo, debe haber al menos un lenguaje cuyas declaraciones se puedan expresar, mediante una sintaxis bien definida, como cadenas de caracteres y que respalde de forma integral los siguientes aspectos:
Definición de datos
Definición de vistas
Manipulación de datos (interactiva y por programa)
Restricciones de integridad
Límites de transacción (begin, commit y rollback).
Regla 6: Regla de actualización de vistas. Todas las vistas que son teóricamente actualizables son también actualizables por el sistema.
Regla 7: Inserción, actualización y borrado de alto nivel. La capacidad de gestionar una relación base o una relación derivada como un solo operando no solo se aplica a la recuperación de los datos, sino también a la inserción, actualización y eliminación de datos.
El sistema debe permitir la manipulación de alto nivel en los datos, es decir, sobre conjuntos de tuplas. Esto significa que los datos no solo se pueden recuperar de una base de datos relacional a partir de filas múltiples y/o de tablas múltiples, sino que también pueden realizarse inserciones, actualizaciones y borrados sobre varias tuplas y/o tablas al mismo tiempo y no solo sobre registros individuales.
Regla 8: Independencia física de los datos. Los programas de aplicación y actividades terminales permanecen inalterados a nivel lógico cuando se realizan cambios en las representaciones de almacenamiento o en los métodos de acceso.
Regla 9: Independencia lógica de los datos. Los programas de aplicación y actividades terminales permanecen inalterados a nivel lógico cuando se realizan cambios en las tablas base que preservan la información.
La independencia de datos lógica es más difícil de lograr que la independencia física de datos.
Regla 10: Independencia de la integridad. Las restricciones de integridad específicas para una determinada base de datos relacional se deben poder definir en el sublenguaje de datos relacional y almacenar en el catálogo, no en los programas de aplicación.
Las restricciones de integridad se deben especificar por separado de los programas de aplicación y almacenarse en la base de datos. Debe ser posible cambiar esas restricciones sin afectar innecesariamente a las aplicaciones existentes.
Regla 11: Independencia de la distribución. El usuario final no ha de ver que los datos están distribuidos en varias ubicaciones. Los usuarios deben tener siempre la impresión de que los datos se encuentran en un solo lugar.
La distribución de porciones de base de datos en distintas localizaciones debe ser transparente para los usuarios de la base de datos. Los usos existentes deben continuar funcionando con éxito:
Cuando una versión distribuida del SGBD se carga por primera vez
Cuando los datos existentes se redistribuyen en el sistema.
Regla 12: La regla de la no subversión. Si un sistema relacional tiene un lenguaje de bajo nivel (un registro cada vez), ese nivel bajo no puede utilizarse para subvertir o eludir las reglas y restricciones de integridad expresadas en el lenguaje relacional de alto nivel (varios registros cada vez).
En resumen podría decirse una base de datos es relacional si cumple cierta cantidad de reglas.
Reglas Seguidas |
Tipo de BD |
|---|---|
Reglas < 6 |
No Relacional |
6 < Reglas < 9 |
Semi Relacional |
9 < Reglas |
Relacional |
Conclusión#
El diseño relacional constituye la base sobre la cual se construyen la mayoría de los sistemas de bases de datos modernos. Comprender los conceptos del modelo relacional, las propiedades de las relaciones, las reglas de Codd, y la correcta implementación de claves y reglas de integridad es esencial para desarrollar bases de datos eficientes, seguras y escalables. Además, el uso de un diccionario de datos asegura que todos los elementos de la base de datos estén bien documentados y fácilmente accesibles, mejorando la coherencia y la capacidad de mantenimiento a lo largo del tiempo.